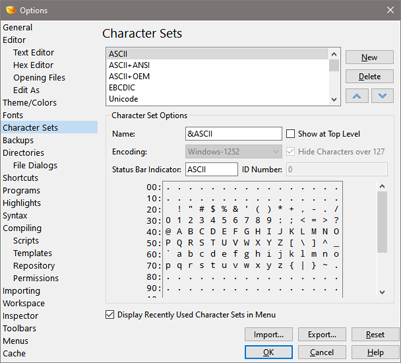
A character set is a mapping from a set of raw hex bytes into a set of characters that can be displayed on the screen. The list of all available character sets can be accessed in the Character Sets dialog, accessed by clicking the 'Tools > Options...' menu option and selecting Character Sets from the list. To assign a character set to a file use the 'View > Character Set' menu. Typically all files that use a particular Edit As have the same character set, but a character set can be assigned on a per-file basis by unchecking the 'View > Character Set > Use Default' toggle.
010 Editor has two main types of character sets: simple and complex (also called multi-byte). Simple character sets (for example ASCII+ANSI) have only 256 different characters and each byte represents a different character. A complex or multi-byte character set (for example Chinese Simplified) has more than 256 characters and multiple bytes are sometimes needed to represent a single character. For the Unicode character set every two bytes indicate one character and Unicode also uses the endian setting from the 'View > Endian' menu when converting from bytes to characters. Some character sets have a variable number of bytes per character and UTF-8 can have between 1 and 4 bytes per character. Characters are sometimes listed in Unicode code-point notation U+XXXX where XXXX is a hexadecimal number. For example the Unicode code-point U+007B is the character '{'. Characters that have no representation in the editor (e.g. control characters) are displayed as '.' in hex-mode or a square in text-mode. The following character sets are available by default:
- ASCII - Standard character set for bytes 0 to 127.
- ASCII+ANSI - ASCII plus encoding Windows 1252 for bytes 128 to 255.
- ASCII+OEM - ASCII plus encoding CP437 for bytes 128 to 255.
- EBCDIC - Encoding EBCDIC 037.
- Unicode - Encoding UTF-16 and uses 2 bytes per character.
- UTF-8 - Encoding UTF-8 and uses 1 to 4 bytes per character.
- Macintosh - An older macintosh character set.
- Arabic (Windows) - Encoding Windows-1256.
- Arabic (ISO) - Encoding ISO-8859-6.
- Baltic (Windows) - Encoding Windows-1257.
- Baltic (ISO) - Encoding ISO-8859-13.
- Chinese (Simplified) - Encoding GB18030 and is compatible with GBK and GB2312.
- Chinese (Traditional) - Encoding Big5.
- Cyrillic (Windows) - Encoding Windows-1251.
- Cyrillic (KOI8-R) - Encoding KOI8-R.
- Cyrillic (KOI8-U) - Encoding KOI8-U.
- Cyrillic (ISO) - Encoding ISO-8859-5.
- Eastern Europe (Windows) - Encoding Windows-1250.
- Eastern Europe (ISO) - Encoding ISO-8859-2.
- Greek (Windows) - Encoding Windows-1253.
- Greek (ISO) - Encoding ISO-8859-7.
- Hebrew (Windows) - Encoding Windows-1255.
- Hebrew (ISO) - Encoding ISO-8859-8.
- Japanese (Shift_JIS) - Encoding Shift_JIS.
- Japanese (EUC-JP) - Encoding EUC-JP.
- Korean - Encoding EUC-KR.
- Thai - Encoding TIS-620.
- Turkish (Windows) - Encoding Windows-1254.
- Turkish (ISO) - Encoding ISO-8859-9.
- Vietnamese - Encoding Windows-1258.
The list of available character sets is available at the top of this dialog and can be reordered with the Up and Down arrows. Clicking New creates a copy of the currently selected character set. The default character sets cannot be modified so a copy of the character set must be created before edits can be made. Clicking Delete removes a character set from the list and the 'View > Character Set' menu but note that any of the standard character sets cannot be deleted.
The name of the character set as appears in the 'View > Character Set' menu can be modified using the Name field. If the Show at Top Level toggle is enabled then the character set will be listed at the top of the Character Set menu. The character set will also be listed in either the Standard, International or Custom area of the 'View > Character Set' menu. The Encoding drop-down list can be used to select the underlying character encoding used from the user interface library and note that the encoding cannot be changed for the default character sets (create a custom character set with the New button to modify the encoding). The Hide Characters over 127 toggle is used for the ASCII character set to hide all characters greater than 127. The Status Bar Indicator field controls which text is displayed in the Status Bar when the character set is active. The ID Number field displays the internal number of this character set that can be used with a number of Template and Script functions. Usually one of the character constants listed in the ConvertString function is used instead of the ID number, but having an ID number for a custom character set allows that character set to be used in Scripts or Templates. Note that ID numbers for custom character sets should be 1000 or greater.
At the bottom of the Character Sets dialog is a table displaying the chosen character set. For simple character sets all 256 characters are displayed in the table and the starting byte value of each line is displayed along the left-hand side of the table. Moving the mouse over the character set table displays a tool tip containing the character, the byte value, and the character number in Unicode code-point notation (U+XXXX). For complex character sets (for example Chinese Simplified) a scroll bar will appear at the bottom of the table to scroll through all possible values. The values on the left side of the table represent two hex bytes that are converted into a character. When viewing the Unicode character set, 'U+' is displayed at the left side to indicate that Unicode code-points are being viewed. To change the font of the table right-click on the table and choose Change Font or return to the original font by right-clicking on the table and selecting Reset Font.
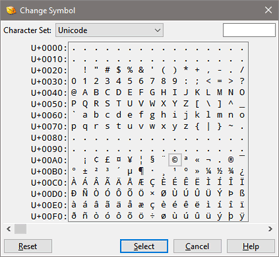
When viewing a simple custom character set, clicking on a character in the character set table opens up the Change Symbol dialog. If clicking on a character of one of the default character sets, you will be asked to copy the character set to a new custom character set before the character set can be modified. Clicking on a symbol in the Change Symbol dialog will switch to using that symbol in the character set and the character will be colored orange in the table. By default the dialog will display characters in the Unicode character set but other character sets can be chosen with the Character Set drop-down list. Click the Reset button in the Change Symbol dialog to return to using the default character. Alternately a symbol can be selected by entering the Unicode code point in hex notation in the field at the top-right of the dialog and then clicking the Select button. Decimal notation can also be used in the field by entering ',d' after the number.
Simple (single-byte) character sets can be exported to a CSV file by clicking the Export... button. The exported file will contain 256 values in hex notation separated by commas and each value represents the Unicode code-point of that character. For example:
...
0x20AC,0xFFFD,0x201A,0x0192,0x201E,0x2026,0x2020,0x2021,
0x02C6,0x2030,0xFFFD,0x2039,0x0152,0xFFFD,0xFFFD,0xFFFD,
...
Clicking the Import... button will allow importing a simple character set into the program. The imported file should contain 256 numbers in decimal notation or 0xXXXX hex notation separated by commas, spaces or tabs. In an imported file the special number -1 can be used to indicate no change for a character in the table.
By default, a list of up to four recently used character sets which do not have the Show at Top Level toggle enabled are shown near the top of the 'View > Character Set' menu. To disable the display of the recently used character sets turn off the Display Recently Used Character Sets in Menu toggle. Click the Reset button to delete all custom character sets and restore all default character sets to their original values.
| 



